如果此时输出data中结果,如图1所示。此图帮助大家了解目前DataFrame中的情况。
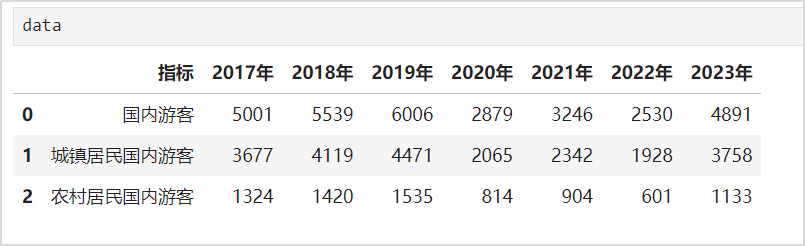
图1 输出data中的结果
data.columns[1:] 表示DataFrame data的所有列名,从第二列开始到最后一列。data.columns 返回 DataFrame 的所有列名,是一个 Index 对象。[1:] 是切片操作,从索引 1 开始(即第二列),取到最后一个列名。此操作输出的结果存储到years中,years的结果如图2所示。

图2 输出years中的结果
data.loc[data['指标'] == '国内游客', years].iloc[0].values 这个表达式的作用是从 DataFrame data 中筛选出 ‘指标’ 列等于 ‘国内游客’ 的行,并选取指定年份列的数据,然后取第一个匹配行的数据,并将其转换为 NumPy 数组。data['指标'] == '国内游客':这是一个布尔索引,用于筛选‘指标’列中值为‘国内游客’的行。data.loc[筛选条件, 年份列]:loc 是基于标签的索引,这里使用筛选条件和年份列名来选择数据。years 是一个数组或列表,包含要选取的年份列名。.iloc[0]:iloc 是基于整数位置的索引,这里取第一个匹配的行。.values:将 Series 对象转换为 NumPy 数组。
此时输出domestic_tourists中的信息,如图3所示。

图3 输出domestic_tourists中的结果
同理,urban_tourists = data.loc[data['指标'] == '城镇居民国内游客', years].iloc[0].values 这个表达式的含义与之前类似,但这次筛选的是‘指标’ 列中值为‘城镇居民国内游客’的行,rural_tourists = data.loc[data['指标'] == '农村居民国内游客', years].iloc[0].values 的含义是从 DataFrame data 中筛选出 ‘指标’ 列等于 ‘农村居民国内游客’ 的行,并选取指定年份列的数据,然后取第一个匹配行的数据,并将其转换为 NumPy 数组。






