

词云图技术与应用解析
一、可视化词云图的应用场景
1.新闻报道
在新闻报道中,词云图可以帮助记者快速梳理出热点事件的核心词汇。通过对新闻标题中出现的关键词进行统计,词云图可以将这些关键词按照权重进行排序,形成一个视觉化的热点词汇分布图。这样,记者可以迅速了解新闻事件的焦点,为报道提供有力的依据。
2.社交媒体
在社交媒体中,用户发布的文字、图片和视频等内容构成了一个庞大的信息网络。通过词云图分析,我们可以发现用户关注的焦点、热门话题以及情感倾向等信息。例如,对于一场公益活动的宣传,我们可以通过词云图分析出用户关注的核心词汇,从而优化宣传策略,提高活动的影响力。
3.舆情监控
在企业和政府部门中,舆情监控是一项重要的工作。通过对网络上的用户评论、发帖等数据进行分析,可以及时发现潜在的危机,为企业决策提供有力支持。词云图可以帮助我们快速识别出舆情关注的焦点,从而采取相应的措施进行应对。
4.产品评价
在电商、旅游等行业中,用户对产品和服务的评价是影响购买决策的重要因素。通过词云图分析,我们可以发现用户关注的核心词汇,如产品质量、价格、服务等方面。这些信息对于企业改进产品和服务具有重要的参考价值。
5.教育培训
在教育培训领域,词云图可以帮助教师和学生更好地理解课程内容。通过对教材中的重点知识点进行词云分析,教师可以更好地把握教学重点,学生也可以更清晰地掌握知识点之间的关系。此外,词云图还可以用于知识竞赛、论文查重等场景,提高学习效率。
6.广告投放
在广告投放过程中,词云图可以帮助广告商更好地了解目标受众的需求和兴趣。通过对广告标题中的关键词进行统计,词云图可以将这些关键词按照权重进行排序,形成一个视觉化的热点词汇分布图。这样,广告商可以更精准地进行广告创意设计,提高广告效果。
7.在数据分析报告中,词云图可以帮助分析师更直观地展示数据特征。通过对报告中的关键数据进行词云分析,分析师可以更好地把握数据的变化趋势和规律,为决策提供有力支持。
总之,词云图作为一种直观、形象的数据可视化手段,在文本分析中具有广泛的应用前景。通过词云图,我们可以快速了解文本中的热点词汇,挖掘出有价值的信息,为各类场景提供有力的支持。
二、基于wordcloud库绘制词云图
词云Wordcloud是文本数据的一种可视化表示方式。它通过设置不同的字体大小或颜色来表现每个术语的重要性。词云在社交媒体中被广泛使用,因为它能够让读者快速感知最突出的术语。然而,词云的输出结果没有统一的标准,也缺乏逻辑性。对于词频相差较大的词汇有较好的区分度,但对于颜色相近、频次相近的词汇来说效果并不好。因此词云不适合应用于科学绘图。本知识拓展内容基于python库wordcloud来绘制词云。wordcloud安装方式如下:
pip install wordcloud
wordcloud库关于绘制词云的相关函数均由其内置类WordCloud提供。
WordCloud类初始函数如下:
WordCloud(font_path=None, width=400, height=200, margin=2,
ranks_only=None, prefer_horizontal=.9, mask=None, scale=1,
color_func=None, max_words=200, min_font_size=4,
stopwords=None, random_state=None, background_color='black',
max_font_size=None, font_step=1, mode="RGB",
relative_scaling='auto', regexp=None, collocations=True,
colormap=None, normalize_plurals=True, contour_width=0,
contour_color='black', repeat=False,
include_numbers=False, min_word_length=0, collocation_threshold=30)
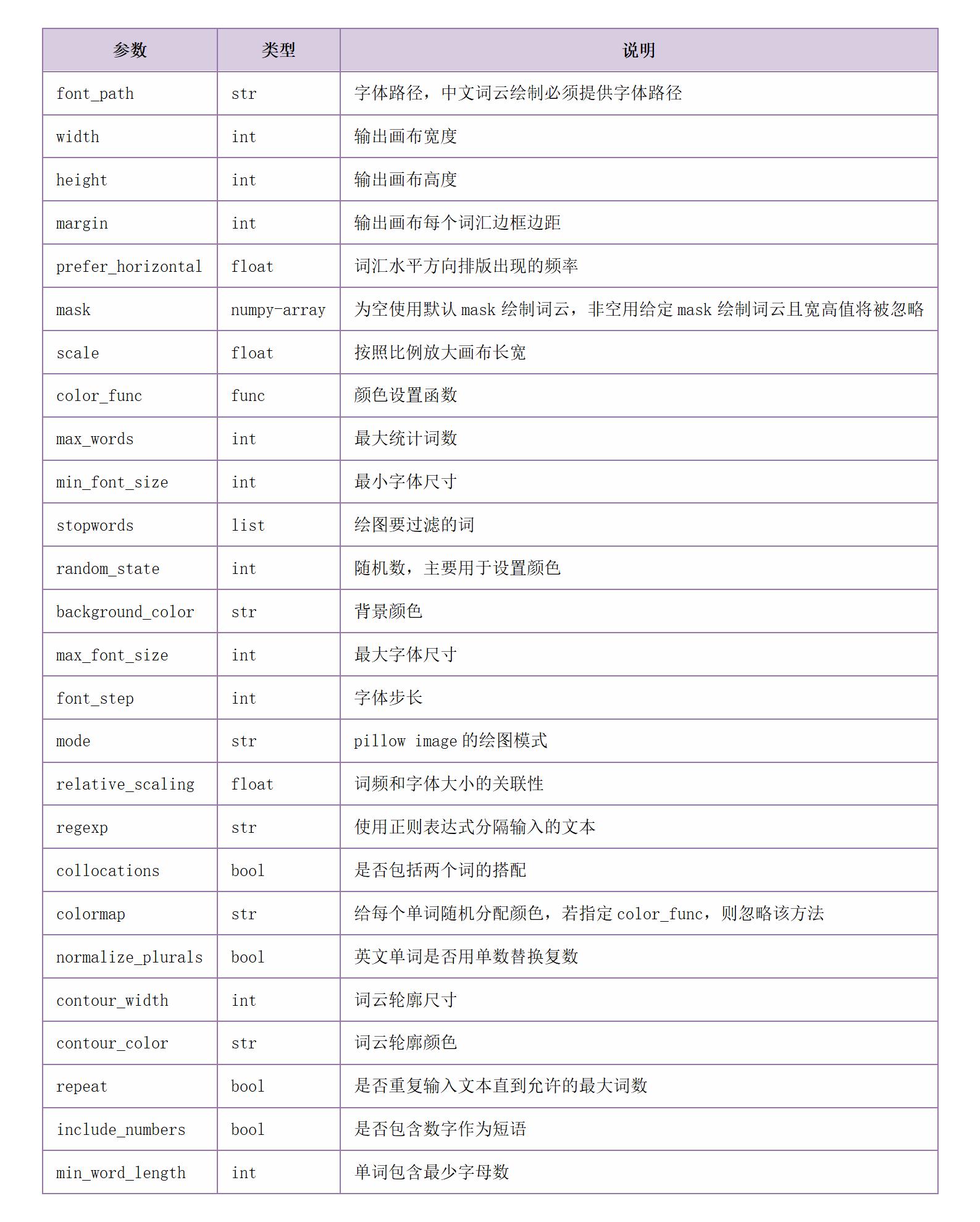
初始函数参数介绍见下表。
WordCloud类提供的主要函数接口如下:
generate_from_frequencies(frequencies):根据词频生成词云
fit_words(frequencies):等同generate_from_frequencies函数
process_text(text):分词
generate_from_text(text):根据文本生成词云
generate(text):等同generate_from_text
to_image:输出绘图结果为pillow image
recolor:重置颜色
to_array:输出绘图结果为numpy array
to_file(filename):保存为文件
to_svg:保存为svg文件
以下为绘图示例代码:
import jieba
import wordcloud
import matplotlib.pyplot as plt
import imageio
mk = imageio.v2.imread("gexing.jpeg")
with open("wenben.txt","r",encoding="utf-8") as f:
txt = f.read()
ls = jieba.lcut(txt)
#对中文文章进行分词,提取文章中的词语,返回一个列表类型的分词结果
txt = " ".join(ls)
#使用join方法可以将列表中的字符串类型的数据,组合成一个字符串。
w = wordcloud.WordCloud(width=1000,height=800,font_path="msyh.ttc",
mask=mk,max_words=400,stopwords=['的','和','是','了'])
w.generate(txt)
w.to_file('shuju.png')
plt.figure(figsize=(20,8))
plt.imshow(w)
plt.axis("off")
plt.show()
小贴士
jieba是优秀的中文分词第三方库,由于中文文本之间每个汉字都是连续书写的,我们需要通过特定的手段来获得其中的每个词组,这种手段叫作分词,我们可以通过jieba库来完成这个过程。因为 jieba 是一个第三方库,所以需要我们在本地进行安装。在命令行中使用pip安装jieba库:
pip install jieba
imageio是一个非常实用的Python库,用于读取、写入和操作图像数据。在Python中,有许多库可以处理图像,但是imageio库具有简单易用、支持多种文件格式和高效的性能等特点,使其成为许多Python开发者的首选。首先,我们需要安装imageio库。您可以使用pip命令来安装imageio:
pip install imageio
安装完成后,就可以开始使用imageio库了。在上面的代码中,我们首先导入了imageio模块,然后使用imread()函数读取了一张JPEG格式的图像。最后使用matplotlib库显示了图像。




