

数据可视化技术解析
一、数据可视化的预处理
数据可视化的预处理主要包括数据清洗、数据集成、数据变换和数据归约。数据清洗是删除或修正错误数据,确保数据的准确性和一致性;数据集成是将来自不同来源的数据合并在一起,解决数据冲突问题;数据变换是对数据进行规范化或聚合,使其适合建模;数据归约则是通过减少数据量来提高处理效率,如维度归约和数据压缩。这些预处理步骤为数据可视化提供了一个干净、统一和高效的数据基础。例如,数据清洗不仅包括删除空值和重复数据,还包括识别和修正异常值,从而提升数据分析和可视化结果的可靠性。
1.数据清洗
数据清洗是大数据预处理的关键步骤,旨在识别和修正错误数据,确保数据的准确性和一致性。这个过程包括以下几个方面:
①删除空值和重复数据:空值和重复数据会影响分析的准确性,因此需要通过算法或手动筛选进行删除。
②识别和修正异常值:异常值可能是数据录入错误或其他原因引起的,识别这些异常并进行修正是确保数据质量的重要步骤。
③处理不一致的数据格式:不同数据源可能使用不同的格式,如日期格式、货币格式等,需要统一为标准格式。
④纠正数据偏差:数据采集过程中可能存在偏差,需要通过统计方法进行纠正。
数据清洗不仅提高了数据的质量,还为后续的数据集成、变换和归约打下坚实基础。
2.数据集成
数据集成是将来自不同来源的数据合并在一起,解决数据冲突和冗余问题。这个过程包括以下几个方面:
①数据源识别与选择:选择可靠的数据源是数据集成的第一步,需要考虑数据的质量和相关性。
②数据匹配与融合:将不同来源的数据进行匹配,融合成统一的数据集,例如通过主键或外键进行关联。
③解决数据冲突:不同数据源可能存在数据冲突,如同一实体的不同描述,需要通过规则或算法进行合并和冲突解决。
✬数据冗余消除:合并数据过程中可能产生冗余,需要通过去重和数据精简技术消除冗余数据。
数据集成为数据分析和可视化提供了一个完整且一致的数据视图。
3.数据变换
数据变换是将原始数据转换为适合分析和可视化的格式,这个过程包括以下几个方面:
①数据规范化:将数据按比例缩放到同一范围内,例如将所有值缩放到0到1之间,以消除不同量纲之间的影响。
②数据聚合:根据某些维度对数据进行聚合,如按月、按地区汇总数据,以便于观察整体趋势。
③数据离散化:将连续数据转换为离散数据,如将年龄分段为不同区间,以便于分类和分析。
④特征工程:从原始数据中提取和创建新的特征,以提高模型的表现。
数据变换通过优化数据格式和结构,使得数据更适合后续的分析和可视化任务。
4.数据归约
数据归约是通过减少数据量来提高处理效率,这个过程包括以下几个方面:
①维度归约:通过主成分分析(PCA)、线性判别分析(LDA)等方法,减少数据的维度,保留重要特征。
②数据压缩:通过数据压缩技术,如无损压缩和有损压缩,减少数据存储空间。
③数据抽样:从大数据集中抽取代表性样本,以减少数据处理量和计算成本。
④特征选择:通过相关性分析和特征重要性评估,选择重要特征,剔除冗余和无关特征。
数据归约不仅提高了计算效率,还减少了存储和传输成本,为大数据分析和可视化提供了更好的性能支持。
二、数据可视化的基本原理——视觉通道
数据可视化为了达到增强人脑认知的目的,会利用不同的视觉通道对冰冷的数据进行视觉编码。
我们在数据可视化的时候,一方面,展现可视化对象本身的位置、特性,对应的视觉通道类型是定性或者分类,比如汽车在什么地方、汽车的种类;另一方面,展现对象的某一个属性值大小,对应的视觉通道类型是定量或者定序,汽车的油耗、汽车加油的排队顺序。下面介绍几种常见的视觉通道。
1. 用于分类的视觉通道
图1所示平面位置在所有的视觉通道中比较特殊,一方面,平面上相互接近的对象会被分成一类,所以位置可以用来表示不同的分类;另一方面,平面使用坐标来标定对象的属性大小时,位置可以代表对象的属性值大小,即平面位置可以映射定序或者定量的数据,比如下面会讲到的「坐标轴位置」。平面位置又可以被分为水平和垂直两个方向的位置,它们的差异性比较小,但是受到重力场的影响,人们更容易分辨出高度,而不是宽度,所以垂直方向的差异能被人们快速意识到,这就解释了为什么计算机屏幕设计成 16∶9、4∶3,这样的设计可以使得两个方向的信息量达到平衡。
图2所示是色调图,我们认识色调只会从定性的角度,平常我们所说的「冷暖色调」,就是我们看一个东西、一幅图,它所表现出来的情感强烈程度,这没法从定量的角度去判别冷艳或是热烈的色调。认识色调,我们要明白这三点:纯色就是色调;向纯色(色调)增加黑色就构成了暗色;向纯色(色调)增加白色就构成了亮色。

图1 位置

图2 色调
形状所代表的含义很广,一般理解为对象的轮廓,或者对事物外形的抽象,用来定性描述一个东西,比如圆形、正方形,更复杂一点是几种图形的组合,如图3所示。
图3 形状
图案也被称为纹理,大致可以被分为自然纹理、人工纹理。自然纹理是自然世界中存在的有规则模式的图案,比如树木的年轮;人工纹理是指人工实现的规则图案,比如中学课本上求阴影部分的面积示意图。如图4所示。

图4 图案
由于纹理可以看作是对象表面或者内部的装饰,所以可以将纹理映射到线、平面、曲面、三维体的表面中,以分类不同的事物。
2. 用于定量/定序的视觉通道
坐标轴上的位置就是前面的位置中的定量功能,使用坐标轴对数据的大小关系进行定量或者排序操作。如图5所示。

图5 坐标轴位置
长度也被称为一维尺寸,当尺寸比较小的时候,其他的视觉通道容易受到影响,比如一个很大的红色正方形比一个红色的点更容易让人区别,人们对很小的形状也无法区别。如图6所示。
![]()
图6 长度
根据史蒂文斯幂次法则,人们对一维的尺寸,即长度或宽度,有清晰地认识。随着维度的增加,人们的判断越来越不清楚,比如二维尺寸(面积)。因此,在可视化的过程中,我们往往将重要的数据用一维尺寸来编码。
角度还有一个名字叫做「方向」,方向不仅仅可以用来分类,也可以用来排序,这得看我们可视化的时候选择什么样的象限。如图7所示。
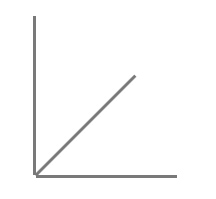
图7 角度
在二维可视化的世界里,四个象限可以有三种用法:在一个象限内表示数据的顺序;在两个象限内表现数据的发散性;在四个象限内可以对数据进行分类。如图8所示。
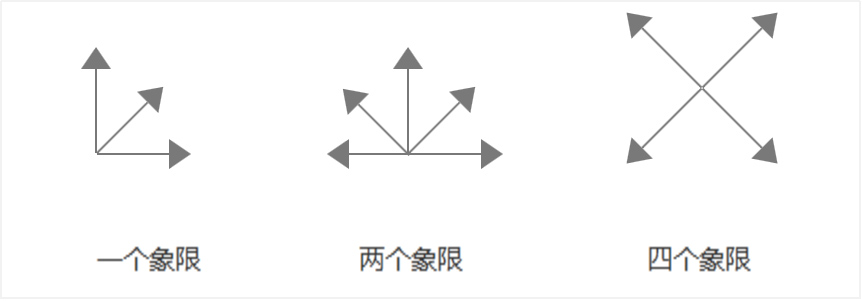
图8 象限
亮度(luminance)是表示人眼对发光体或被照射物体表面的发光或反射光强度实际感受的物理量。简而言之,当两个物体表面在照相时被拍摄出的最终结果是一样亮或被眼睛看起来两个表面一样亮,它们就是亮度相同。在可视化方案中,尽量使用少于 6 个可辨识的亮度层次,两个亮度层次之间的边界也要明显。如图9所示。

图9 亮度/饱和度
饱和度指的是色彩的纯度,也叫色度或彩度,是“色彩三属性”之一。如大红就比玫红更红,这就是说大红的色度要高。饱和度跟尺寸有很大的关系,区域大的适合用低饱和度的颜色填充,比如散点图的背景;区域小的使用更亮、颜色更加丰富、饱和度更高的颜色加以填充,便于用户识别,比如散点图的各个散点。小区域使用的饱和度通常只有 3 层,大区域的可以适当增加一些。如图10所示。

图10 图案密度
图案密度是表现力最弱的一个视觉通道,在实际应用中很少看到它的身影。可以把它当作同一形状、尺寸、颜色的对象的集合,用来表示定量或定序的数据。
小贴士
视觉通道的分类不是唯一的,比如位置信息,既能区分不同的分类,又可以用来表示连续数据的差异,所以在数据可视化的过程中,我们应该根据需要做一定调整。




